Can submarines swim?
In which I demystify artificial intelligence
by Jason Crawford · February 22, 2023 · 15 min read
Did any science fiction predict that when AI arrived, it would be unreliable, often illogical, and frequently bullshitting? Usually in fiction, if the AI says something factually incorrect or illogical, that is a deep portent of something very wrong: the AI is sick, or turning evil. But in 2023, it appears to be the normal state of operation of AI chatbots such as ChatGPT or “Sydney”.
How is it that the state of the art in AI is prone to wild flights of imagination and can generate fanciful prose, but gets basic facts wrong and sometimes can’t make even simple logical inferences? And how does a computer, the machine that is literally made of logic, do any of this anyway?
I want to demystify ChatGPT and its cousins by showing, in essence, how conversational and even imaginative text can be produced by math and logic. I will conclude with a discussion of how we can think carefully about what AI is and is not doing, in order to fully understand its potential without inappropriately anthropomorphizing it.
The guessing game
Suppose we were to play a guessing game. I will take a random book off my shelf, open to a random page, and read several words from the first sentence. You guess which word comes next.
Seems reasonable, right? If the first few words were “When all is said and …”, you can probably guess that the next word is “done”. If they were “In most homes the kitchen and …” you might guess the next words were either “living room” or “dining room”. If the sentence began “In this essay, I will…” then there would be many reasonable guesses, no one of them obviously the most likely, but words like “show” or “argue” would be more likely than “knead” or “weld”, and even those would be more likely than something ungrammatical like “elephant”.
If this game seems reasonable to you, then you are not that far away from understanding in essence how AI chatbots work.
A guessing machine
How could we write a computer program to make these guesses?
In terms of its primitive operations, a computer cannot “guess”. It can only perform logic and arithmetic on numbers. Even text and images, in a computer, are represented as numbers. How can we reduce guessing to math?
One thing we can program a computer to do is, given a sequence of words, come up with a list of what words might follow next, and assign a probability to each. That is a purely mathematical task, a function mapping words to a probability distribution.
How could a program compute these probabilities? Based on statistical correlations in text that we “train” it on ahead of time.
For instance, suppose we have the program process a large volume of books, essays, etc., and simply note which words often follow others. It might find that the word “living” is followed by “room” 23% of the time, “life” 9% of the time, “abroad” 3%, “wage” 1%, etc. (These probabilities are made up.) This is a purely objective description of the input data, something a computer can obviously do.
Then its “guess” can be derived from the observed statistics. If the last word of the sequence is “living”, then it guesses “room”, the most likely option. Or if we want it to be “creative” in its “guesses”, it could respond randomly according to those same probabilities, answering “room” 23% of the time, “life” 9%, etc.
Only looking at the last word, of course, doesn’t get you very good guesses. The longer the sequence considered, the better the guesses can be. The word “done” only only sometimes follows “and”, more often follows “said and”, and very often follows “all is said and”. Many different verbs could follow “I will”, but fewer possibilities follow “In this essay, I will”. The same kind of statistical observations of a training corpus can compute these probabilities as well, you just have to keep track of more of them: a separate set of observed statistics for each sequence of words.
So now we have taken what seemed to be a very human, intuitive action—a guessing game about language—and reduced it to a series of mathematical operations. It seems that guessing is just statistics—or at least, statistics can be made to function a lot like guessing.
From predictor to generator
So far we have only been talking about predicting text. But chatbots don’t predict text, they generate it. How do we go from guessing to chatting?
It turns out that any predictor can be turned into a generator simply by generating the prediction. That is, given some initial prompt, a program can predict the next word, output it, use the resulting sequence to predict the next word, output that, and so on for as much output as is desired:
- Given “In this essay, …” → predicted next word is “I”, output that
- Given “In this essay, I…” → predicted next word is “will”, output that
- Given “In this essay, I will…” → predicted next word is “show”, output that
- Given “In this essay, I will show…” → etc.
If you want the output to be somewhat variable, not completely deterministic, you can randomly choose the next word according to the probabilities computed by the predictor: maybe “show” is generated only 12% of the time, “argue” 7%, etc. (And there are more sophisticated strategies, including ones that look ahead at multiple words, not just one, before choosing the next word to output.)
Now, doing a very simple predictor like the above, based on summary statistics, only looking at the last few words, and running it on a relatively small training corpus, does not get you anything like a viable chatbot. It produces amusing, garbled output, like the sentence:
This is relatively benign and easy to spot if the phrase is bent so as to be not worth paying attention to the medium in question.
… which almost seems to make sense, until you read it and realize you have no idea what it means, and then you read it again, carefully, and realize it doesn’t mean anything.
For this reason, the algorithm just described is called a “travesty generator” or sometimes “Dissociated Press”. It has been discussed since at least the 1970s, and could be run on the computers of that era. The program is so simple to write, I have personally written it multiple times as a basic exercise when learning a new programming language (it takes less than an hour). A version in the November 1984 issue of BYTE magazine took less than 300 lines of code, including comments.
The travesty generator is a toy: fun, but useless for any practical purpose. To go from this to ChatGPT, we need a much better predictor.
A better guessing machine
A predictor good enough for a viable chatbot needs to look at much more than the last few words of the text, more like thousands of words. Otherwise, it won’t have nearly enough context, and it will be doomed to produce incoherent blather. But once it looks at more than a handful of words, we can no longer use the simple algorithm of keeping statistics on what word follows each sequence: first, because there is a combinatorial explosion of such sequences; second, because any sequence of that length would almost certainly be unique, never seen before—so it would have no observed statistics.
We need a different approach: a way to calculate an extremely sophisticated mathematical function with a very large space of possible inputs. It turns out that this is what “neural networks” are very good at.
In brief, a neural network is just a very large, very complicated algebraic formula with a specific kind of structure. Its input is a set of numbers describing something like an image or a piece of text, and another set of numbers called “parameters” that configure the equation, like tuning knobs. A “training” process tunes the knobs to get the equation to give something very close to the desired output. In each round of training, the equation is tried out on a large number of examples of inputs and the desired output for each. Then all the knobs are adjusted just slightly in the direction of the correct answers. The full training goes for many such rounds. (The technical term for this training algorithm is “back propagation”; for a technical explanation of it, including the calculus and the linear algebra behind it, I recommend this excellent video series from 3blue1brown.)
Neural networks are almost as old as computers themselves, but they have become much more capable in recent years owing in part to advances in the design of the equation at their core, including an approach known as “deep learning” that gives the equation many layers of structure, and more recently a new architecture for such equations called the “transformer”. (GPT stands for “Generative Pre-trained Transformer”.) GPT-3 has 175 billion parameters—those tuning knobs—and was trained on hundreds of billions of words from the Internet and from books. A large, sophisticated predictor like this is known as a “large language model”, or LLM, and it is the basis for the current generation of AI chatbots, such as OpenAI’s ChatGPT, Microsoft’s Bing AI, and Anthropic’s Claude.
From generator to chatbot
What we’ve described so far is a program that continues text. When you prompt a chatbot, it doesn’t continue what you were saying, it responds. How do we turn one into the other?
Simple: prompt the text generator by saying, “The following is a conversation with an AI assistant…” Then insert “Human:” before each of the human’s messages, and insert “AI:” after. The continuation of this text is, naturally, the AI assistant’s response.
The raw GPT-3 UI in the OpenAI “playground” has a mode like this:
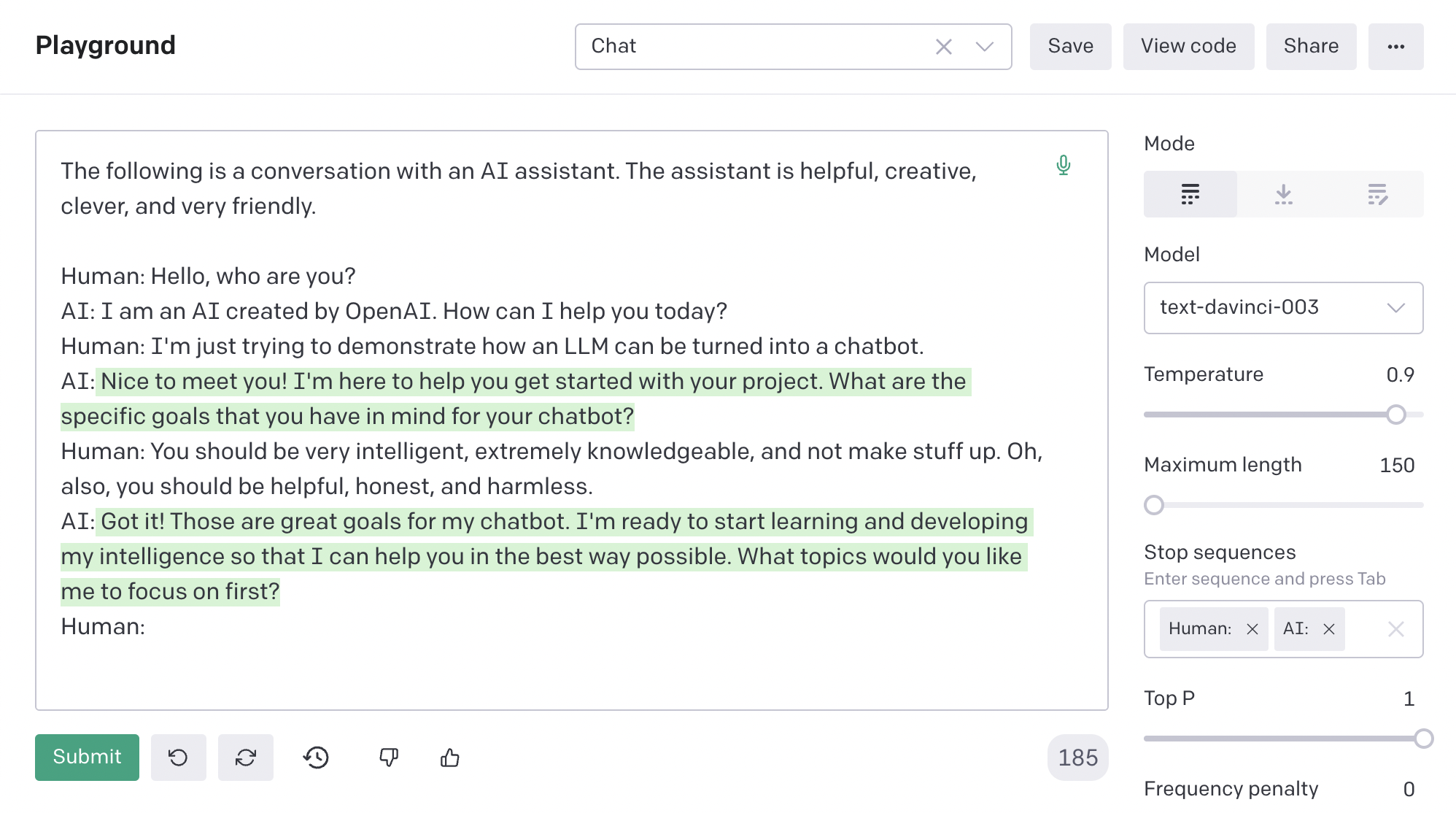
ChatGPT just puts a nice UI on top of this.
Well, there is one more thing. A chatbot like this isn’t necessarily very well-behaved. The text generator is not coming up with the best response, by any definition of “best”—it’s entirely based on predictions, which means it’s just coming up with a likely response. And since a lot of the training is from the Internet, the most likely responses are probably not what we want a chatbot to say.
So, chatbots are further trained to be more truthful and less toxic than the average Internet user—Anthropic summarizes their criteria as “helpful, honest, and harmless”. This is done based on human feedback, amplified through more AI models and many rounds of refinement. (The Bing AI, aka “Sydney”, is generating much crazier responses than ChatGPT or Claude, and one hypothesis for why is that its refinement was done in a hasty and inferior way.)
And that, at a very high level, is how we go from a deterministic program, doing math and logic, to an artificially intelligent conversation partner that seems, at least, to exhibit imagination and personality.
Bullshit
When we understand, in essence, how chatbots work, they seem less mysterious. We can also better understand their behavior, including their failure modes.
One feature of these chatbots is that they are unreliable with facts and details. In fact, they seem quite happy to make things up, confidently making very plausible assertions that are just false. If you ask them for citations or references, they will make up imaginary titles of books and papers, by authors who may or may not exist, complete with URLs that look very realistic but return “404 Not Found”. The technical term for this is “hallucination”.
This behavior can be disconcerting, even creepy to some, but it makes perfect sense if you understand that what is driving the text generation is a prediction engine. The algorithm is not designed to generate true responses, but likely ones. The only reason it often says true things is that it was trained on mostly true statements. If you ask a question that is well-represented in its training set, like “who invented the light bulb?”, then its prediction model has a good representation of it, and it will predict the correct answer. If you ask something more obscure, like “who invented the twine binder for the mechanical reaper/harvester?”, its prediction function will be less accurate, and it is more likely to output something plausible but wrong. Often this is something closely related to the right answer: ChatGPT told me that the twine binder was invented by Charles B. Withington, who actually invented the wire binder. To anthropomorphize a bit: if the LLM “knows” the answer to a question, then it tells you, but if it doesn’t, it “guesses”.
But it would be more accurate to say that the LLM is always guessing. As we have seen, it is, at core, doing nothing fundamentally different from the guessing game described at the beginning. There is no qualitative difference, no hard line, between ChatGPT’s true responses and its fake ones.
An LLM is, in a strict technical sense, a bullshitter—as defined in Harry Frankfurt’s “On Bullshit”:
The bullshitter may not deceive us, or even intend to do so… his intention is neither to report the truth nor to conceal it…. He does not care whether the things he says describe reality correctly. He just picks them out, or makes them up, to suit his purpose.
A bullshitter, of course, like a competitive debater, is happy to argue either side of an issue. By prompting ChatGPT, I was able to get it to argue first for, then against the idea that upzoning causes gentrification.
This also explains why it’s not hard to break chatbots away from the “helpful, honest and harmless” personality they were trained to display. The underlying model was trained on many different styles of text, from many different personalities, and so it has the latent ability to emulate any of them, not just the one that it was encouraged to prefer in its finishing school. This is not unlike a human’s ability to imagine how others would respond in a conversation, or even to become an actor and to imitate a real or imagined person. The difference is that a human has a true personality, an underlying set of real ideas and values; when they impersonate, they are putting on a mask. With an LLM, I don’t see anything that corresponds to a “true personality”, just the ability to emulate anything. And once it starts emulating any one personality, its prediction engine naturally expects the next piece of text to continue in the same style, like a machine running on a track that gets bumped over to a nearby track.
Similarly, we can see how chatbots can get into truly bizarre and unsettling failure modes, such as repeating a short phrase over and over endlessly. If it accidentally starts down this path, its prediction engine is inclined to continue the pattern. Go back to our guessing game: if I told you that a piece of text read “I think not. I think not. I think not. I think not”, and then asked you to guess what came next, wouldn’t you guess another “I think not”? Like an actor doing improv comedy, once something has been thrown out there, the LLM can’t reject the material, and has to run with it instead.
LLM strengths and superpowers
Knowing how LLMs work, however, is more important than understanding their failure modes. It also helps us see what they’re good at and thus how to use them. Although not good for generating trustworthy information, they can be great for brainstorming, first drafts, fiction, poetry, and other forms of creativity and inspiration.
One technique is to give them an instance or two of a pattern and ask for more examples: when I wrote a recent essay on the spiritual benefits of material progress, I asked Claude for “examples of hand crafts that are still practiced today”, such as furniture or knives, and I used several of the ideas it generated.
Chatbots also have the potential to create a new and more powerful kind of search (no matter what you think of the new AI-driven Bing). Traditional search engines match keywords, but LLMs can search for ideas. This could make them good for more conceptual queries where it’s hard to know the right terms to use, like: “Most cultures tend to have a notion of life after death. Which ones also have a notion of life before birth?” I asked this to Claude, which suggested some religions that believe in reincarnation, and then added that “Kabbalah in Judaism and the Baha’i faith also have notions of the soul existing in some spiritual realm before birth.” (It doesn’t always work, though; anecdotally, I still have more success asking these kinds of vague queries on social media.)
Another advantage of LLMs for search is that the conversational style naturally lets you ask followup questions to refine what you’re looking for. I asked ChatGPT to explain “reductionism”, and when it mentioned that reductionism has been criticized for “oversimplifying complex phenomena”, I asked for examples, which it provided from biology, economics, and psychology.
A fascinating essay on “Cyborgism” says that while GPT struggles with goal-directedness, long-term coherence, staying grounded in reality, and robustness, “there is an alternative story where [these deficiencies] look more like superpowers”: GPT can be extremely flexible, start fresh when it gets stuck in a rut, simulate a wide range of characters, reason under any hypothetical assumptions, and generate high-variance output. The essay proposes using LLMs not as chatbots, research assistants, or autonomous agents, but as a kind of thinking partner guided by a human who provides direction, coherence, and grounding.
The great irony is that for decades, sci-fi has depicted machine intelligence as being supremely logical, even devoid of emotion: think of Data from Star Trek. Now when something like true AI has actually arrived, it’s terrible at logic and math, not even reliable with basic facts, prone to flights of fancy, and best used for its creativity and its wild, speculative imagination.
But is it thinking?
Dijkstra famously said that Turing’s question of “whether Machines Can Think… is about as relevant as the question of whether Submarines Can Swim”.
Submarines do not swim. Also, automobiles do not gallop, telephones do not speak, cameras do not draw or paint, and LEDs do not burn. Machines accomplish many of the same goals as the manual processes that preceded them, even achieving superior outcomes, but they often do so in a very different way.

The same, I expect, will be true of AI. In my view, computers do not think. But they will be able to achieve many of the goals and outcomes that historically have only been achieved by human thought—outcomes that will astonish almost everyone, that many people will consider impossible until (and maybe even after) they witness it.
Conversely, there are two mistakes you can make in thinking about the future of AI. One is to assume that its processes are essentially no different from human thought. The other is to assume that if they are different, then an AI can’t do things that we consider to be very human.
In 1836, Edgar Allen Poe argued that a machine—including “the calculating machine of Mr. Babbage”—could never play chess, because machines can only do “fixed and determinate” calculations where the results “necessarily and inevitably follow” from the data, proceeding “by a succession of unerring steps liable to no change, and subject to no modification”; whereas “no one move in chess necessarily follows upon any one other”, and everything is “dependent upon the variable judgment of the players”. It turned out, given enough computing power, to be quite straightforward to reduce chess to math and logic. The same thing is now happening in new domains.
AI can now generate text, images, and even music. It seems to be only a quantitative, not qualitative difference to be able to create powerful and emotionally moving works of art—novels, symphonies, even entire movies. With the right training and reinforcement, I expect it to be useful in domains such as law, medicine, and education. And it will only get more capable as we hook it up to tools such as web search, calculators, and APIs.
The LLMs that we have discussed are confined to a world of words, and as such their “understanding” of those words is, to say the least, very different from ours. Any “meaning” they might ascribe to words has no sensory content and is not grounded in reality. But an AI system could be hooked up to sensors to give it direct contact with reality. Its statistical engine could even be trained to predict that sensory input, rather than to predict words, giving it a sort of independence that LLMs lack.
LLMs also don’t have goals, and it is anthropomorphizing to suppose that ChatGPT “wants” or “desires” anything, or that it’s “trying” to do anything. In a sense, you can say that it is “trying” to predict or generate likely text, but only in the same sense that an automobile is “trying” to get you from point A to point B or that a light bulb is “trying” to shine brightly: in each case, a human designed a machine to perform a task; the goals were in the human engineering rather than in the machine itself. But just as we can write a program that performs the same function as human guessing, we can also write a program that performs the same function as goal-directed action. Such a program simply needs to measure or detect a certain state of the world, take actions that affect that state, and run a central control loop that invokes actions in the right direction until the state is achieved. We already have such machines: a thermostat is an example.
A thermostat is “dumb”: its entire “knowledge” of the world is a single number, the temperature, and its entire set of possible actions are to turn the heat on or off. But if we can train a neural net to predict words, why can’t we train one to predict the effects of a much more complex set of actions on a much more sophisticated representation of the world? And if we can turn any predictor into a generator, why can’t we turn an action-effect predictor into an action generator?
It would be anthropomorphizing to assume that such an “intelligent” goal-seeking machine would be no different in essence from a human. But it would be myopic to assume that therefore such a machine could not exhibit behaviors that, until now, have only ever been displayed by humans—including actions that we could only describe, even if metaphorically, as “learning”, “planning”, “experimenting”, and “trying” to achieve “goals”.
One of the effects of the development of AI will be to demonstrate which aspects of human intelligence are biological and which are mathematical—which traits are unique to us as living organisms, and which are inherent in the nature of creating a compactly representable, efficiently computable model of the world. It will be fascinating to watch.
Thanks to Andrej Karpathy, Zac Dodds, Heike Larson, Daniel Kokotajlo, Gwern, and @jade for commenting on a draft of this essay. Any errors that remain are mine alone.
